1. 문제
[본 문제는 정확성과 효율성 테스트 각각 점수가 있는 문제입니다.]
세로길이가 n 가로길이가 m인 격자 모양의 땅 속에서 석유가 발견되었습니다. 석유는 여러 덩어리로 나누어 묻혀있습니다. 당신이 시추관을 수직으로 단 하나만 뚫을 수 있을 때, 가장 많은 석유를 뽑을 수 있는 시추관의 위치를 찾으려고 합니다. 시추관은 열 하나를 관통하는 형태여야 하며, 열과 열 사이에 시추관을 뚫을 수 없습니다.

예를 들어 가로가 8, 세로가 5인 격자 모양의 땅 속에 위 그림처럼 석유가 발견되었다고 가정하겠습니다. 상, 하, 좌, 우로 연결된 석유는 하나의 덩어리이며, 석유 덩어리의 크기는 덩어리에 포함된 칸의 수입니다. 그림에서 석유 덩어리의 크기는 왼쪽부터 8, 7, 2입니다.

시추관은 위 그림처럼 설치한 위치 아래로 끝까지 뻗어나갑니다. 만약 시추관이 석유 덩어리의 일부를 지나면 해당 덩어리에 속한 모든 석유를 뽑을 수 있습니다. 시추관이 뽑을 수 있는 석유량은 시추관이 지나는 석유 덩어리들의 크기를 모두 합한 값입니다. 시추관을 설치한 위치에 따라 뽑을 수 있는 석유량은 다음과 같습니다.
시추관의 위치획득한 덩어리총 석유량| 1 | [8] | 8 |
| 2 | [8] | 8 |
| 3 | [8] | 8 |
| 4 | [7] | 7 |
| 5 | [7] | 7 |
| 6 | [7] | 7 |
| 7 | [7, 2] | 9 |
| 8 | [2] | 2 |
오른쪽 그림처럼 7번 열에 시추관을 설치하면 크기가 7, 2인 덩어리의 석유를 얻어 뽑을 수 있는 석유량이 9로 가장 많습니다.
석유가 묻힌 땅과 석유 덩어리를 나타내는 2차원 정수 배열 land가 매개변수로 주어집니다. 이때 시추관 하나를 설치해 뽑을 수 있는 가장 많은 석유량을 return 하도록 solution 함수를 완성해 주세요.
2. 접근
열을 검사했을 때 바로 연결된 석유의 개수를 알면 되지 않을까? 로 시작
그러기 위해서는 map[i][j]를 확인했을 때 석유 그룹의 번호와 석유 그룹의 크기를 알아야 한다.
1. 그룹번호와 그룹 크기 알아내기
BFS로 탐색하면서 그룹번호를 저장한다. 아래와 같은 형태로

int bfs(int groupNumber, int r, int c, boolean [][] isVisited, int[][] land){
Queue<Point> que = new LinkedList();
int count = 0;
que.add(new Point(r,c));
isVisited[r][c] = true;
int [] dr = {0, -1, 0, 1};
int [] dc = {1, 0, -1, 0};
while(!que.isEmpty()){
Point cur = que.poll();
land[cur.r][cur.c] = groupNumber;
count++;
for(int i=0; i<4; i++){
int nr = cur.r + dr[i];
int nc = cur.c + dc[i];
if(nr <0|| nr >=N || nc <0 || nc >=M){
continue;
}
if(isVisited[nr][nc] || land[nr][nc] == 0){
continue;
}
que.add(new Point(nr, nc));
isVisited[nr][nc] = true;
}
}
return count;
}
}
그리고 그룹의 크기를 `HashMap`에 저장해서 바로 데이터를 꺼내올 수 있도록 한다.
int count = bfs(groupNumber, i, j, isVisited,land);
countMap.put(groupNumber++, count);
2. 열 탐색하면서 최대값 갱신
이제 열을 차례로 탐색하면서 얻을 수 있을 석유의 개수를 알아낸다.
// 2. 하나씩 열 탐색하면서 최대치 구하기
int max = 0;
for(int j=0; j<M; j++){
int curNumber = -1;
int curMax = 0;
for(int i=0; i<N; i++){
// 0 이 아니고
if(land[i][j] == 0){
continue;
}
// 이전번호와 같지 않음 - 개수 추가
if(land[i][j] != curNumber){
curNumber = land[i][j];
curMax += countMap.get(curNumber);
}
}
// max 값 갱신
max = Math.max(max, curMax);
}밑으로 쭉 내려가니깐 중복 카운팅하지 않도록 현재 그룹 번호를 저장한다. 그리고 현재 그룹 번호와 같지 않을 때, 즉 새로운 그룹을 만났을 때 석유의 양을 더한다.
3. 결과
결과가 처참하다... 왜지?
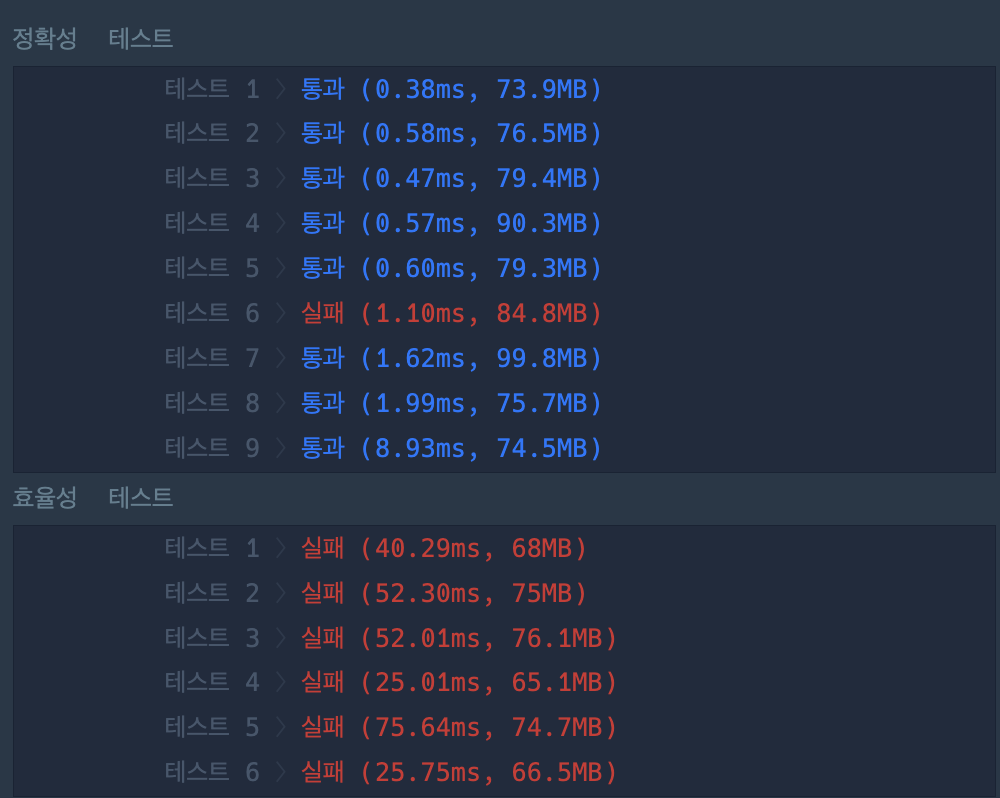
시간복잡도를 따져봤을 때, BFS 탐색을 전체 맵 한 번 돌리니깐 O(2500) 정도, 최대값을 알 때 다시 전체 맵을 도니깐 O(2500)이니깐 괜찮을 줄 알았는데 이 방법보다 훨씬 적게 걸릴 수 있는게 있나보다!
4. 수정
인터넷 검색해보니 방법이 비슷해서 내 코드는 왜 효율성이 낮지? 고민하니깐 예외가 있었다.
테스트6이 통과가 안되는걸 보면 시간이 느린게 아니고 그냥 틀린거였나보다.
놓치 예외는 열 탐색하면서 최대값 갱신 했을 때 중복을 방지해서 바로 직전의 그룹번호와만 같지 않으면 카운팅 했는데 이게 문제였다. 만약 그룹이 ㄷ 형태일 경우에 중간 사이에 여러 개의 그룹이 또 오게 되는 경우 중복 카운팅이 되었다.
그래서 `int curGroupNumber`로 직전 값만 저장하던 방식에서 `Set`을 이용하여 방문한 모든 정보를 저장했더니 무사히 통과했다!
전. 이전 값만 저장
// 이전번호와 같지 않음 - 개수 추가
if(land[i][j] != curNumber){
curNumber = land[i][j];
curMax += countMap.get(curNumber);
}
후. Set으로 모든 값 저장
// 이전번호와 같지 않음 - 개수 추가
int gn = land[i][j];
if(!set.contains(gn)){
set.add(gn);
curMax += countMap.get(gn);
}

5. 전체 코드
import java.util.*;
class Solution {
static int N, M;
static int [][] groupMap;
public int solution(int[][] land) {
// 1. BFS로 그룹번호 map, <number, count> 얻기
N = land.length;
M = land[0].length;
boolean [][] isVisited = new boolean[N][M];
HashMap<Integer, Integer> countMap = new HashMap();
int groupNumber = 1;
for(int i=0; i<N; i++){
for(int j=0; j<M; j++){
if(isVisited[i][j] || land[i][j] == 0){
continue;
}
int count = bfs(groupNumber, i, j, isVisited,land);
countMap.put(groupNumber++, count);
}
}
// 2. 하나씩 열 탐색하면서 최대치 구하기
int max = 0;
Set<Integer> set;
for(int j=0; j<M; j++){
int curNumber = -1;
int curMax = 0;
set = new HashSet();
for(int i=0; i<N; i++){
// 0 이 아니고
if(land[i][j] == 0){
continue;
}
// 이전번호와 같지 않음 - 개수 추가
int gn = land[i][j];
if(!set.contains(gn)){
set.add(gn);
curMax += countMap.get(gn);
}
}
// max 값 갱신
max = Math.max(max, curMax);
}
return max;
}
int bfs(int groupNumber, int r, int c, boolean [][] isVisited, int[][] land){
Queue<Point> que = new LinkedList();
int count = 0;
que.add(new Point(r,c));
isVisited[r][c] = true;
int [] dr = {0, -1, 0, 1};
int [] dc = {1, 0, -1, 0};
while(!que.isEmpty()){
Point cur = que.poll();
land[cur.r][cur.c] = groupNumber;
count++;
for(int i=0; i<4; i++){
int nr = cur.r + dr[i];
int nc = cur.c + dc[i];
if(nr <0|| nr >=N || nc <0 || nc >=M){
continue;
}
if(isVisited[nr][nc] || land[nr][nc] == 0){
continue;
}
que.add(new Point(nr, nc));
isVisited[nr][nc] = true;
}
}
return count;
}
}
class Point{
int r;
int c;
public Point(int r, int c){
this.r = r;
this.c = c;
}
}
6. 회고
우선 정확성에서 모두 통과가 되야지 효율성을 따질 수 있나보다.
그리고 코딩할 때 주석으로 할 일을 적어두고 시작하니 걸리는 시간도 줄어들고 중간에 막히지도 않았다. 좋은 방법같다.
'알고리즘 > 프로그래머스' 카테고리의 다른 글
| [프로그래머스] level2 - 짝지어 제거하기 (0) | 2025.03.17 |
|---|---|
| [프로그래머스] 택배 배달과 수거하기 level2 (Java) - 그리디 (0) | 2025.01.31 |
| [프로그래머스] 퍼즐 게임 챌린지 level2- JAVA (0) | 2025.01.27 |
| [프로그래머스] SQL Level 3 모음(~ing) (0) | 2024.03.01 |
| [프로그래머스] SQL Level1 모음 (0) | 2024.02.20 |