합병 정렬 개념
- 리스트를 두 개의 균등한 크기로 분할하고 분할된 리스트를 정렬한 다음, 두 개의 정렬된 부분 리스트를 합하기를 반복하면서 전체를 정렬한다.
- 분할 정복 기법 알고리즘 중 하나이다.
분할 정복 기법 (divide and conquer)
문제를 작은 2개의 문제로 분리하고 각 문제를 해결 후, 결과를 모아서 원래의 문제를 해결하는 전략
구체적인 알고리즘
합병 정렬은 다음 3가지 단계를 반복하며 정렬을 한다.
- 분할(Divide) : 같은 크기의 2개의 부분 배열로 분할한다.
- 정복(Conquer) : 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 충분히 작아질 때까지 분할을 반복한다.
- 결합(Combine): 정렬된 부분 배열들을 하나의 배열로 통합한다.
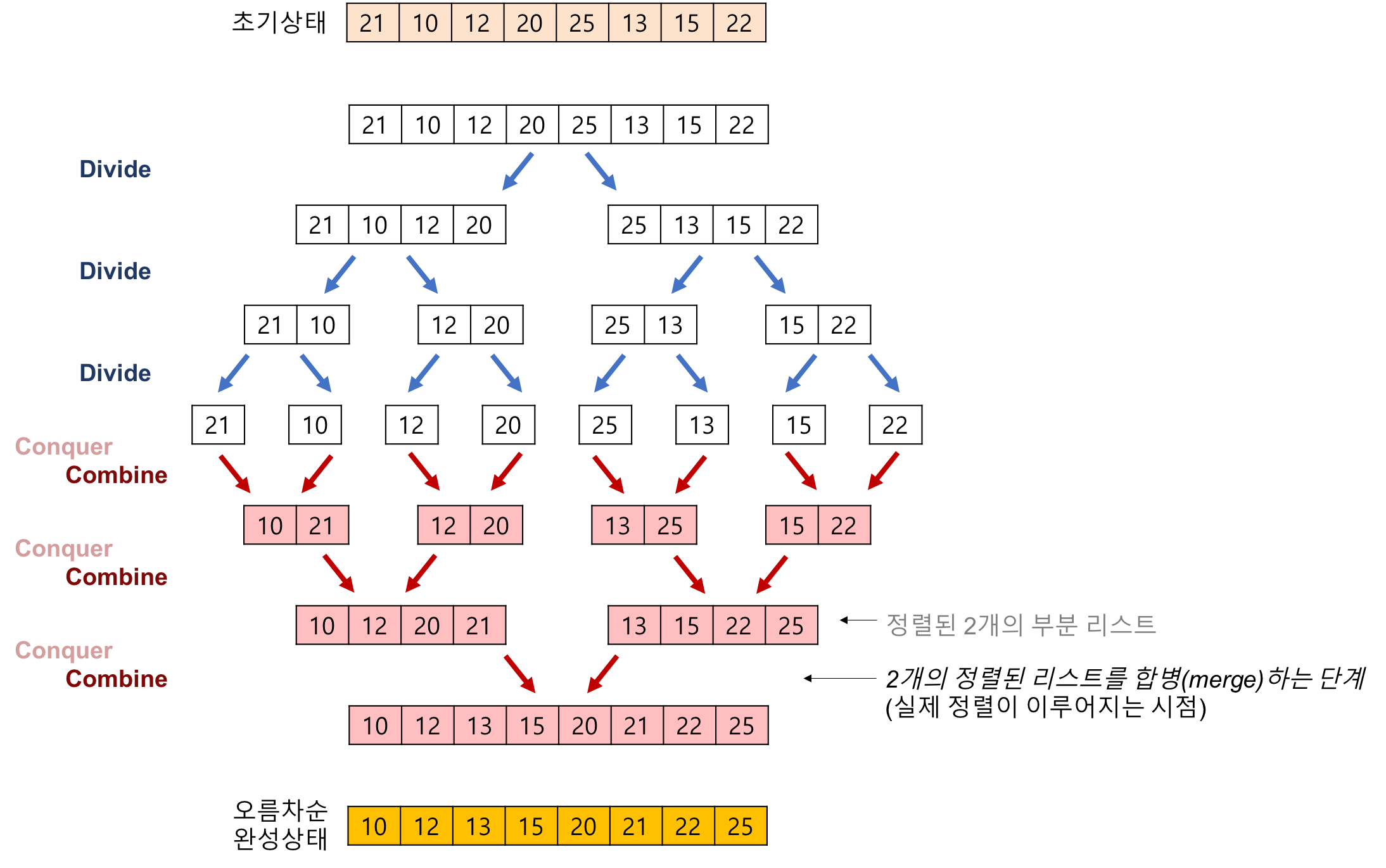
- 부분 리스트의 크기가 1개가 될 때까지 분할을 반복한다.
- 크기를 늘려가며 부분리스트들을 병합한다. 이때 정렬이 이루어진다.
- 추가적인 리스트에서 합병을 진행한 후 원본 배열에 복사한다.
코드 - Java
public static void merge(int list[], int left, int mid, int right){
int i,j,k,l;
i =left; j = mid+1; k = left;
System.out.println("merge 호출 :" + left + "~ " + right);
/* 분할 정복된 list의 합병 */
while (i <= mid && j <= right){
if(list [i] <= list[j]){
sorted[k++] = list[i++];
}else{
sorted[k++] = list[j++];
}
}
if(i>mid){ /* 남아 있는 레코드 일괄 복사 */
for(l=j ; l <= right; l++){
sorted[k++] = list[l];
}
}
else{ /* 남아 있는 레코드 일괄 복사 */
for(l=i ; l <= right; l++){
sorted[k++] = list[l];
}
}
/* 배열 sorted[]의 리스트를 배열 list[]로 복사 */
for(l=left; l<= right; l++){
list[l] = sorted[l];
}
}
public static void merge_sort(int list [], int left, int right){
int mid;
System.out.println("merge_sort 호출 :" + left + "~ " + right);
if(left < right){
mid = (left + right)/2;
merge_sort(list, left, mid);
merge_sort(list, mid+1, right);
merge(list, left, mid, right);
}
}
실행 결과
입력 배열 [5,4,3,2,1] 데이터로 해당 정렬 함수를 호출하면 다음과 같이 함수가 호출된다. 점점 2로 나누어 분할을 진행하다 부분 리스트 원소의 개수가 1개가 될 때 분할을 멈추고 merge를 진행한다. 첫 merge 함수 호출시 처음 입력되었던 순서를 기준으로 0과 1번째 요소가 정렬된다. 원본 배열에서 정렬을 진행하므로 첫 merge 함수의 결과는 [4,5,3,2,1] 이 된다. 두 번째 merge 함수는 0~2 인덱스의 데이터를 합병하여 결과는 [3,4,5,2,1]이 된다. 이때 merge_sort (2,2) 부분이 의아했는데 이는 원소의 개수가 홀수라서 { [0,1], [2] } 로 나뉘어서 그렇다. 세 번째 merge 함수의 결과는 [3,4,5,1,2] 이 되고 최종적으로 [1,2,3,4,5]가 된다.

시간복잡도
분할할 때 호출의 깊이(k)
데이터의 크기가 n이고 n이 2의 거듭 제곱이라고 가정할 때, 2^k = n 이다. 분할을 진행할 때 2^k -> 2^(k-1) -> ... -> 2^0 순으로 줄어들어 호출의 깊이는 k이다. 그러므로 k = logn이 된다.
이동 연산
- 이동 연산과 비교연산은 합병할 때 일어난다.
- 임시 배열에 복사하고 원래 원복에 다시 복사해야하기 때문에 한 번의 합병 단계에서 2n번 이동이 일어난다.
- 2n*logn
비교 연산
- 하나의 합병 단계에서 n번의 비교 연산이 필요
- 2*4, 4*2, 8*1
- n*longn
합병 정렬의 시간 복잡도 : O(nlogn)
합병 정렬의 특징
장점
- 최악, 평균, 최선 모두 O(nlogn)인 정렬 방법이다.
- 안정적인 정렬 방법이다.
단점
- 임시 배열이 필요하여 메모리 차지가 크다.
- 이동 횟수가 많아 레코드들의 크기가 크면 불리한다. 하지만 연결리스트로 구현하면 링크 인덱스만 변경하면 되어 효율적이게 될 수 있다.
'CS > 알고리즘' 카테고리의 다른 글
| [알고리즘] Lower bound와 Upper bound 개념과 구현 - Java (0) | 2023.11.10 |
|---|---|
| Java BFS와 DFS 구현 (0) | 2023.09.17 |
| 퀵 정렬 (Quick Sort) - Java (0) | 2023.08.17 |
| 삽입 정렬 - Java (0) | 2023.08.16 |
| 버블 정렬 - Java (0) | 2023.08.14 |