컴파일러 개념을 하나도 몰라서 직접 인터프리터를 만들어보며 공부하고자 한다.
추가로 인터프리터를 C++로 언어로 만들어보면서 C++ 문법도 같이 학습하고자 한다!
우선 인터프리터의 내부 작동이 어떻게 이루어지는지 하나도 모르기 때문에 전체적인 구조와 컴파일러에 대해 알아보자.
소스코드가 실행 파일이 되기까지의 과정
컴파일러는 크게 프론트엔드(Front-end), 백엔드(Back-end) 두 부분으로 나뉜다.

프론트 엔드
- 전처리 (Preprocessing)
- 비유: 번역 전 원고를 정리하는 단계. 여러 개의 원고 파일을 하나로 합치고, 약어를 풀어쓰는 작업.
- 입력: C 소스 코드 파일 (.c)
- 처리:
- #include <stdio.h> 같은 지시문을 만나면 stdio.h 파일의 내용을 그대로 가져와 붙여넣는다.
- #define PI 3.14 같은 매크로를 만나면 코드 내의 모든 PI를 3.14로 바꾼다.
- 주석(//, /* */)을 모두 제거한다.
- 출력: 모든 코드가 합쳐지고 매크로가 치환된, 여전히 C 언어 형태인 하나의 거대한 텍스트 파일
- 어휘 분석(Lexical Analysis)
- 비유: 원고의 문장을 의미 있는 토큰(Token) 단위로 자르는 작업.
- 입력: 전처리가 끝난 C 소스 코드
- 처리: 긴 텍스트 스트림을 의미 있는 최소 단위인 토큰(Token)으로 분해한다. 예를 들어 int a = 10;는 int, a, =, 10, ; 이라는 5개의 토큰으로 나뉜다.
- 출력: 토큰들의 연속적인 스트림(배열 또는 리스트)
- 구문 분석 (Syntax Analysis)
- 비유: 잘라낸 단어들을 가지고 문법에 맞게 문장 구조를 만드는 작업이다. '주어-목적어-동사' 순서가 맞는지 확인하는 것과 같다.
- 입력: 토큰 스트림
- 처리: 토큰들의 순서가 C 언어 문법 규칙에 맞는지 검사하면서, 코드의 구조를 나무 형태로 표현하는 **추상 구문 트리(AST)**를 만든다. 여기서 문법에 맞지 않는 코드(예: int a = ;)가 발견되면 구문 오류(Syntax Error)를 발생시킨다.
- 출력: AST (추상 구문 트리)
- 의미 분석
- 비유: 문법적으로는 완벽한 문장이지만, 의미가 말이 되는지 확인하는 작업.
- 입력: AST
- 처리: AST를 분석하여 코드의 의미가 올바른지 확인.
- 타입 검사: 정수형 변수에 문자열을 넣으려고 하는지 (int a = "hello";)
- 선언 검사: 선언되지 않은 변수를 사용하고 있는지
- 변수의 유효 범위(Scope) 검사 등
- 출력: 의미 정보가 추가되고 검증된 AST
백엔드
- 최적화
-
- 비유 : 번역할 문장을 더 간결하고 효율적으로 다듬는 편집 및 교정단계이다.
- 입력 : 의미 분석이 끝난 AST
- 처리:
- AST를 특정 CPU나 OS에 종속되지 않는 **중간 표현(Intermediate Representation, IR)**으로 변환한다.
- 이 중간 코드를 분석하여 더 효율적으로 만들 수 있는 부분을 찾아 최적화한다.
- 절대 실행되지 않는 코드 제거
- 24 * 60 처럼 결과가 정해진 계산을 미리 해버리기 (1440으로 바꿈)
- 반복문(loop)을 더 효율적인 구조로 변경
- 출력: 최적화된 중간 코드(IR)중간 코드 및 최적화
- 코드 생성 (Code Generation)
- 비유: 잘 다듬어진 원고를 목표 언어(예: 영어)로 본격적으로 번역하는 작업이다.
- 입력: 최적화된 중간 코드(IR)
- 처리: 중간 코드를 타겟 머신(예: 인텔 x86 CPU)이 이해할 수 있는 어셈블리어로 번역한다. 이 단계부터는 특정 하드웨어에 종속적인 코드가 생성된다.
- 출력: 어셈블리 코드 파일 (.s 또는 .asm)
- 링킹 (Linking)
- 비유: 번역된 본문과 외부에서 가져온 참고문헌(라이브러리)을 합쳐 한 권의 완성된 책으로 엮는 최종 작업이다.
- 입력: 어셈블러가 변환한 목적 파일(.o 또는 .obj) 및 라이브러리 파일
- 처리:
- 어셈블리 코드를 실제 기계어(0과 1)로 이루어진 **목적 파일(Object file)**로 변환한다.
- 이 목적 파일과 우리가 코드에서 사용한 printf 같은 함수가 들어있는 라이브러리 파일을 연결(link)한다.
- OS가 프로그램을 실행할 수 있도록 필요한 정보들을 추가하여 최종 실행 파일을 만든다.
- 출력: 최종 실행 파일 (.exe 또는 a.out)
공부하면서 느낀 것은 과연 인터프리터와 컴파일러가 뭐가 다른거지? 였다. 내가 만들고자 하는 것은 인터프리터인데 내부 구조를 찾아보면 컴파일러 작동 방식이 나왔다. 컴파일러와 인터프리터의 차이점을 알아보자.
컴파일러와 인터프리터의 차이
이때까지 내가 알고있던 지식은
인터프리터는 한줄 한줄 번역하며 실행한다.
컴파일러는 전체를 한 번만 컴파일해서 한 번에 실행한다.
이었다. 크게 보면 맞긴하지만 정확한 의미는 모르고 있었다. 그래서 나는 인터프리터와 컴파일러가 아예 틀린 건줄 알았다.
하지만 막상 내부 구조를 보면 두 개를 명확히 구분할 수 없을 정도로 매우 비슷하다. 두 개 모두 소스 코드를 토큰화하고 전처리하고 의미 분석을 걸쳐 "중간 표현"을 만들어낸다. 여기까지는 과정이 동일하지만 차이점은 중간 표현을 어떻게 "사용"하냐에 있다.
인터프리터는 지금 당장 실행을 목표로 중간 코드를 바로 번역 및 실행을 한다.
컴파일러는 실행 할 수 있는 파일을 만드는 것을 목표로 중간 코드를 가지고 최적화를 진행한 다음 하나의 실행 파일(ex) exe 파일)을 만들어 낸다.
그래서 위에서 언급한 프론트엔드의 동작까지는 인터프리터와 컴파일러가 같다. 이로서 내가 만들어야 하는 것은 프론트 엔드의 영역이다.
각 영역을 자세히 알아보자.
어휘분석 (Lexical Analysis)
l어휘 분석의 가장 큰 일은 코드를 토큰화 시키는 것이다. 토큰은 의미가 있는 최소 단위를 말한다. 예를 들어 `int x = 10` 라는 코드가 있으면 여기서 토큰은 4개이다.
| int | Identity |
| x | name |
| = | Assign |
| 10 | Integer Literal |
토큰의 정의는 언어마다 다르며, 구현하고자 하는 언어에 맞게 식별하면 된다.
아래는 C언어의 일부 Lexical Rules이다.
Lexical Rules
letter ::= a | b | … | z | A | B | … | Z (오직 알파벳만)
digit ::= 0 | 1 | …| 9 (정수형)
id ::= letter{ letter } (오직 알파벳만)
intcon ::= digit{digit}
이렇게 이미 다 정의가 되어있다. 정의된 포맷에 맞춰 토큰 단위로 잘라낸다.
구문 분석 (Syntax Analysis)
구문 분석이란 문법에 맞는 문장 구조를 만드는 작업이다.(문장 구조 또한 언어를 구현하기 전에 이미 정의되어 있어야 한다.) 구문 분석(Syntax Analysis)은 parser가 진행한다.
입력으로 토큰 스트림을 받고, 토큰들의 순서가 문법 규칙에 맞는지 검사하면서 코드의 구조를 아래와 같은 트리 형태로 만든다. 이때 세미콜론이나 띄어쓰기 같은 불필요한 것 들은 제외하고, 필요한 정보들로만 구성한다 해서 추상 구문 트리(ATS)라고 한다.
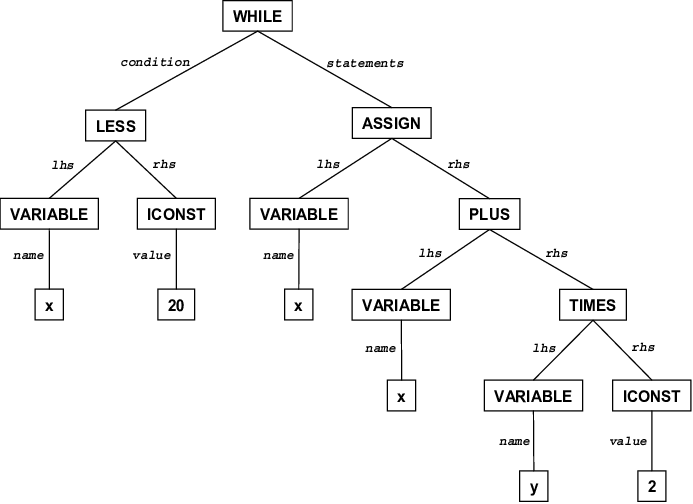
여기서 문법에 맞지 않는 코드가 발견되면 구문 오류(Syntax Error)를 발생시킨다.
예를 들어보면,
C언어의 일부 Syntax Rules은 아래와 같다.
Syntax Rules
Prog ::= {dcl ’;’ | func }
dcl ::= type var_decl
var_decl ::= id [ '[' intcon ']' ]
type ::= int
params::= ε
func ::= ( type | **void ) id ’(’ params ‘)’ ‘{’{type var_decl ’;’}’{stmt}’}’
stmt ::= return [ expr ] ';' | assg ';' | '{' { stmt } '}' | ';'
assg ::= id = expr
expr ::= intcon | id | id '(' [ expr { ',' expr } ] ')' //함수 | '(' expr ')' | expr binop expr
binop ::= + | - | * | /
이 중 var_decl ::= id [ '[' intcon ']' ] 을 살펴보자.
여기서 말하는 id란 Lexical Rules에서 정의된 id ::= letter{ letter } 을 말한다. 1개 이상의 문자가 오면 된다는 표현이고, '['는 있어도 되고 없어도 된다는 표현이다. 저 표기대로면 `count = 10` 혹은 `count = [20]`이 var_decl 이다.
즉 구문 분석은 Sysntax Rules이 지켜졌는지 확인하고, 검사를 하면서 트리 형태를 만들어낸다.
여기서 언어를 정의하는 표기법이 EBFN 표기법(Backus-Naur form)인데 알아두면 Rule을 이해하기 편하다.
EBFN 문법
BFN란?
베커스-나우르(Backus-Naur form)
<기호> ::= <표현식>
- ::= : 정의
- | : OR
- <> : 비단말 기호
EBNF란?
BFN에 4가지 메타 기호 추가한 확장된 BNF
- [] : 생략 가능
- {} : 0번 이상 반복 가능
- () : 안에 있는 것 중 하나
- 사칙연산 ::=<수식> ( +| - | * | / ) <수식>
의미 분석
의미가 맞는지 확인하는 작업이다. parser에서는 문법적으로 맞는지 확인하고 parsing의 결과로 출력된 AST(Abstraction Syntax Tree)를 분석하여 코드의 의미가 올바른지 확인한다.
예를 들어 int 자료형으로 선언된 변수에 "apple"같은 문자열이 들어가는지, 선언되지 않는 변수를 사용하고자 하는지 검사한다. 나는 이 의미분석을 AST를 실행하는 평가기를 만들 때 함께 구현했다.
여기까지가 front-end의 대략적인 개요였다. 사실 처음엔 잘 이해되지 않았는데 직접 인터프리터를 만들어보면서 점점 잘 알게되고 있다.
바로 구현을 시작하기 전에 마지막으로 인터프리터의 종류도 알아봐야한다. 과연 어떤 형태의 인터프리터를 만들지 정해야 하기 때문에...
사실 인터프리터도 발전 해오면서 그 종류가 여러개이다. 그 중 가장 대표적이 3가지만 알아볼 것이다.
인터프리터 종류
트리 탐색 인터프리터
- 동작 방식
- AST를 직접 순회하면서 각 노드를 만날 때마다 해당 노드가 의미하는 작업을 즉시 실행
- 요리사가 레시피(AST)를 순차적으로 한 줄 한 줄 읽으면서, 그 즉시 실행
- 장/단점
- 렉싱, 파싱, 실행의 각 단계가 명확하게 구분 되어, 처음 교육용으로 좋음
- 하나하나 방문해서 느림
바이트코드 인터프리터
- 동작 방식
- 컴파일 단계
- AST를 다시 한 번 바이트코드(bytecode) 라는 중간 언어로 컴파일
- (Java만인 줄 알았는데 파이썬, c#도 바이트 코드 쓰네)
- 중간 언어니깐 기계어보다는 추상적, ast보다는 기계어에 가깝 (PUSH 5, PUSH 10, ADD 와 같은 형태)
- 가상머신이 바이트 코드를 한 줄씩 읽어들여 실행 함실행 단계
- 컴파일 단계
- 장/단점
- 빠른 속도 : AST의 복잡한 구조 탐색 없이, 단순하고 선형적인 명령어를 처리
- 이식성: 바이트 코드와 VM만 있으면 어떤 환경(윈도우, 맥, 리눅스)이든 코드 실행 가능
- Q. 결국 바이트 코드를 cpu에 종속 되는 것이 아닌 VM에 종속된다는 것? 그럼 VM은 바이너리 코드가 필요없나?→ VM은 결국 실행하는 주체가 아니라 바이트 코드와 기계어를 중간에서 엮어주는 역할이구나
→ 바이트 코드를 CPU가 아닌 VM에 종속된다. 하지만 VM 자체는 결국 OS위에서 돌아가는 프로그램이기 때문에 네이티브 바이너리 코드여야 함.구현 복잡: 바이트 코드 추가 설계, 또한 소스 코드(AST?)를 바이트 코드로 변환하는 컴파일러 만들어야 함. 또한 vm도 만들어야 함
3. JIT 컴파일 인터프리터
- 동작 방식
- 기본적으로 바이트 코드 인터프리터와 동일하게 동작함
- 하지만 실행 중에 **자주 실행되는 코드(Hot Spot)**를 실시간으로 감시하고 분석해서 찾음
- 그 부분만 해당 컴퓨터의 네이티브 기계어로 컴파일해서 직접 실행함.
- 비유
- 요리 보조(VM)가 요리를 하다가, 특정 소스를 계속해서 반복적으로 만드는 것을 발견. 보조는 "이럴 바에야 이 소스를 아예 대량으로 만들어 놓고(네이티브 컴파일), 필요할 때마다 그냥 가져다 쓰자!"라고 결정하는 것
- 장/단점
- 매우 빠름: 인터프리터의 유연함과 컴파일러의 실행 속도를 모두 가짐
- 초기 실행 시 오버헤드 : 코드를 분석하고 컴파일하는 데 시간이 걸림(워밍업 시간)
이 중에서 가장 만들기 쉬운 트리 탐색 인터프리터를 만들 것이다.